
本文由skypacer译自Patterns in C REACTOR,原文作者Adam Petersen。
导语
本篇英文原文所发布的站点Adam Petersen是一个个人网站,本文翻译了其中reactor C实现章节, 水平有限,欢迎指正。
目录
1、多客户端示例
2、单一责任原则
3、违反Open-Closed原则
4、从性能谈起
5、问题总结
6、REACTOR模式
6.1、事件探测
6.2、实现机制
6.3、Reactor注册策略
6.4、Reactor实现
6.5、触发Reactor
6.6、处理注册
6.7、事件多样性
7、REACTOR vs OBSERVER
8、结论
9、总结
正文
本文将研究一种适用于event-driven应用的模式。Reactor Pattern将应用的不同职责解耦,允许应用由多个潜在的client端分离并分发事件。
1、多客户端示例
为了简化对大系统的维护,工程师可以单独搜集子系统的诊断信息然后再合并至中心。每个子系统利用TCP/IP连接至诊断服务器,由于TCP/IP是一个面向连接的协议,客户端(不同的子系统)不得不单独向server请求相应的连接。一旦连接建立,client可以随时发送诊断信息。
为了解决这个问题,最容易想到的方法就是服务器依次扫描客户端的连接请求和诊断信息,如下图所示:
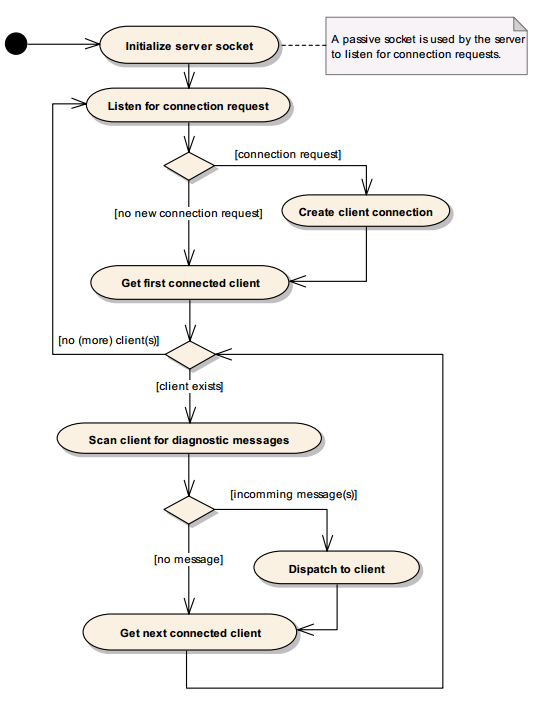
尽管这是一个极其简化的例子,这里仍然存在不少潜在的问题。首先是该方法将应用逻辑、网络代码、事件分发代码这几个毫不相干的逻辑捆绑在一起,会带来严重的维护、测试和可扩展问题,这样的设计违反了基本的设计原则。
2、单一责任原则
单一责任原则,即一个类只能有一种原因去驱动改变,该原则的是同open-closed原则有异曲同工之妙:尽量避免现有代码的修改。当违反了单一原则的时候,一个模块有多种原因需要去修改。更糟的是,多个不同的责任集中于一个模块当中会耦合在一起,使得测试与修改变得非常复杂。
单一责任原则本质是集中性,便于进行多层抽象,而不仅仅是一个过程上下文,简单地讲类替换为函数将有利于我们在此原则基础上分析算法。
3、违反Open-Closed原则
如果违反了Open-Closed原则,上述例子的模块将变得难以维护,或者该代码在设计之初就没打算扩展性。不幸的是,该中设计已经违反了Open-Closed原则,若不改变现有代码,新的功能将无法加入。总而言之,这种设计使得修改代码变得代价高昂。
4、从性能谈起
这种方案的糟糕之处还在于整个系统的性能变得很差,当线性扫描所有事件时,尽快采用了超时机制,然而很多时间被白白浪费了。
一个潜在的性能问题就是并发失败的处理,一种解决方案是引入多线程,诊断服务器轮询事件,但是此时的轮询代价已经只剩下处理连接请求,一旦请求建立,分配相应的线程处理该连接上的所有消息处理。
然后多线程方案无法从根本上解决这种设计的问题:违反了单一责任原则和Open-Closed原则。尽管扫描代码和诊断消息处理从主循环中移除,添加一个新的服务端口仍需修改现有代码。
从设计的角度看,线程不能改变任何事情,事实上,即使考虑到性能,这种改进导致上下文切换和同步,反而比单线程方法更糟。
5、问题总结
总结以上的经验,我们发现上述设计方南的失败之处归结于它们以三种责任为解决前提。问题即违反了Open-Closed原则,导致难于修改现有代码。
理想的解决方案应该是易于扩展、封装和多种责任解耦,并能够同时服务多个客户端,即使不引入多线程。Reactor模式通过在事件处理中封装应用逻辑和在事件分发中隔离代码很好的解决了这些问题。
6、REACTOR模式
Reactor模式定义:“reactor架构使得事件驱动型的不同应用实现分离,并将来自一个或多个客户端的服务请求分发至一个应用中”。
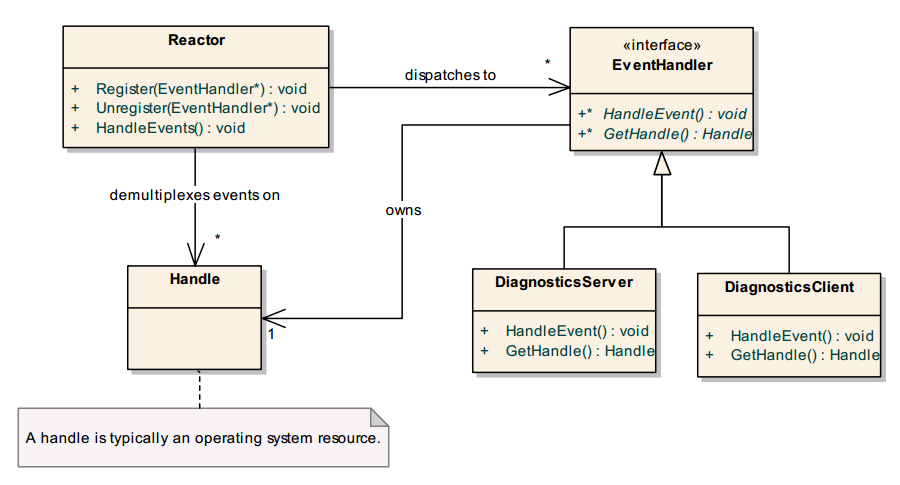
其中包含的参与者如下:
- EventHandler:一个EventHandler定义了一个接口,该接口由处理事件的模块实现,每个EventHandler有自己的Handle。
- Handle:Handle 本质是reactor模式在OS上实现的具体句柄,例如,handle 包含了像文件、socket和timer等系统资源。
- DiagnosticsServer and DiagnosticsClient: 这是两种具体的事件handler,每个独立封装一个责任,为了能够接受事件通知,这些具体的事件handlers必须在 Reactor 中进行注册。
- Reactor:Reactor 维护 EventHandler 的注册,并取出相应的 Handles. Reactor 等待已经注册 handles 中的事件,当 Handle 通知事件发生时,触发相应的 EventHandler 。
6.1、事件探测
在一些文献中关于 reactor 的描述中,定义了一个工具,即 synchronous Event Demultiplexer , 该分离器由 reactor 调用等待已经注册的 Handles 的事件。
该事件分离器一般由操作系统提供,比如 poll() ,select() 和 WaitForMutipleObjects() 。
6.2、实现机制
EventHandler 和 Reactor 之间的合作关系类似OBSERVER模式中的observer和它的对象。
为了将Reactor和它的事件处理器解耦,同时Reactor仍能够通知到他们,每个具体的事件处理器必须关联一个唯一的instance。这里的C实现中,采用void 作为通用类型以描述 *EventHandler 接口。
- 事件处理接口:EventHandler.h
|
|
- Reactor注册接口:ractor.h
|
|
- 具体的事件处理器:DiagnosticsServer.c
|
|
6.3、Reactor注册策略
当实现具体的事件处理器时定义抽象数据结构,这样做的好处是封装具体的注册处理细节,这样就隐藏了具体的信息,client甚至无需了解如何同reactor交互。
Reactor的另外一个好处体现在server内部,比如说对handle的封装通过getServerSocket获得,这样我们为reactor提供一个方式获取handle;同时,reactor对事件处理器进行访问控制:只有注册的事件处理器方可被调用相应的handle及其相关资源。
6.4、Reactor实现
Reactor的实现依赖于具体的同步事件分发器,如果OS提供了多种同步事件分发器,比如select()和poll(),Reactor就需要针对这些分发器实现多个reactor实例,并由链接器根据问题选择,即所谓的链接多态。
每种Reactor的实现必须确定该应用下所需要的reactor实例。在多数场景中,应用只需一个reactor实例,即single reactor。如果应用需要多个reactor实例,则可以对reactor本身进行抽象。
为了独立于具体的分离机制,Reactor必须维护一个已注册具体的事件处理器集合。简单地做法就是采用数组,适用于最大的客户端数目已知的情形。
基于Poll()实现的Reactor:PollReactor.c
|
|
6.5、触发Reactor
反应事件轮询是Reactor的核心,其职责在于根据具体的事件处理器控制已注册事件的分离和分发。事件循环典型由main()函数调用。
驱动reactor的客户端代码如下:
|
|
为了整体设计,需要单独为HandleEvents()创建一个文件实现,PollReactor.c,其中每个元素都将已注册事件的句柄和用于同poll()交互的结构绑定在一起。另外一种替代方案是维护两个不同的链表以确保二者的一致性。UNIX实现采用select(),定义为“一个以UNIX I/O句柄值为索引的数组,范围为0至FD_SETSIZE-1”。
在本实现中,通过将poll结构和注册组合在一起,由于采用数组用于同poll()交互,因此该数组必须在每次事件轮询进入的时刻建立。
6.6、处理注册
在本文的reactor实现中,server通过创建一个新的client来响应通知,这样一来,必须注册方可再次激活。
一种解决方案是维护一个单独的数组用于同同步事件分离器进行交互, 该数组在事件循环中不能被修改。
而句柄的实现则依赖平台,句柄ID有可能被重用;在拷贝中的一个信号句柄有可能属于一个未注册的事件句柄,但是由于注册重用了句柄ID,新的事件处理器可能被错误触发。我们可以加入哨兵数据以标识是否重用来解决该问题。
6.7、事件多样性
实例代码仅仅考虑了一种类型的事件(read事件),其类型是hardcoded。Reactor本身并未受类型限制,能够很好的支持多种类型。
两种通用的事件通知分发机制:
- Single-method interface:所有的事件由单个函数通知事件处理器,函数中只需传入事件类型即可(enum),其不足之处在于加入了额外的控制逻辑,难于维护。
- Multi-method interface:事件处理器为每种支持的事件声明各自的函数(比如会所handleRead, handleWrite, handleTimeout)。一旦Reactor获取已发生事件的类型,它立即触发对应的事件处理函数,这样避免了通过指针重新创建事件的额外开销。
7、REACTOR vs OBSERVER
尽管用于实现二者的机制相关,但是仍存在差异,主要的不同点在于通知机制。在OBSERVER实现中,当一个Subject改变其状态时,它的所有依赖者(observers)都被通知。而在REACTOR实现中,通知的关系式一对一,即一个已探测到的事件导致Reactor通知其对应的实例(EventHandler)。
另外,一个典型的OBSERVER模式下的subject是低内聚的,除了服务其核心目的,一个subject也会负责管理和通知observers。相反,一个Reactor则仅仅分发已经注册的处理器。
8、结论
应用REACTOR模式的主要结论如下:
- 遵循single-responsibility原则的好处:采用REACTOR模式,每种责任被封装并相互之间解耦,导致高内聚,因此简化了后续维护。比如在事件探测中平台相关的代码可以从应用中解耦,极大的方便了单元测试。
- 遵循open-closed原则的好处:新的责任只需创建新的事件处理器,无需影响现有代码。
- 统一了事件处理:尽管REACTOR模式集中于句柄,但其可以扩展至其他任务。Reactor加入timer支持(平台相关,比如基于信号或者线程),当同步事件分离器触发后可以设定一个超时,以避免重入问题和竞争条件。
- 提供了一种并行读的方案:采用REACTOR方案可以有效避免并行读事件处理中的阻塞现象,其本质是一个非抢占式的多任务模型,每个具体的事件处理器必须确保其不能执行可能导致其余事件处理器饥饿的操作。
- 类型安全的折中:由于所有的事件处理器抽象为void *,当由void指针转化为具体的事件处理指针时,编译器并没有相应的机制处理转化错误。同样的问题在OBSERVER模式中也存在,解决方法都是一致的:为不同类型的事件处理器定义单独的通知函数,利用EventHandler绑定事件处理器和其他函数。
9、总结
Reactor模式通过对不同责任的解耦和不同模块的封装简化了事件驱动型应用的设计。关于该模式更多的讨论可以参考面向对象的软件模式卷2。