
本文由skypacer译自Patterns in C REACTOR,原文作者Adam Petersen。
导语
本篇英文原文所发布的站点Adam Petersen是一个个人网站,本文翻译了其中reactor C实现章节, 水平有限,欢迎指正。
目录
1、多客户端示例
2、单一责任原则
3、违反Open-Closed原则
4、从性能谈起
5、问题总结
6、REACTOR模式
6.1、事件探测
6.2、实现机制
6.3、Reactor注册策略
6.4、Reactor实现
6.5、触发Reactor
6.6、处理注册
6.7、事件多样性
7、REACTOR vs OBSERVER
8、结论
9、总结
正文
本文将研究一种适用于event-driven应用的模式。Reactor Pattern将应用的不同职责解耦,允许应用由多个潜在的client端分离并分发事件。
1、如何评估一个系统
我们可以以单位时间内的操作次数定义性能,比如每秒请求数,每秒交易数;
可扩展性: 指通过增加计算资源以提高处理负载的能力,分为水平扩展和垂直扩展;
对于垂直扩展,我们针对单一机器本身,比如用SSD替换HDD,换个更快的CPU等,往往效果有限;
而水平扩展则不然,我们通过增加更多服务器将性能提升至几十倍上千倍,但同时难度也更大,需要确保数据的一致性;
对于WEB服务,如果我们只是单纯增加服务器数量,数据库势必很快将成为瓶颈,因此我们引入cache;
注:这里的数据库一般指传统的关系型数据库,支持用于完成业务逻辑的SQL;
2、Cache
Cache的几个概念:
- cache Size:定义了Cache可保存元素数量;
- 命中率:返回正确结构数/请求缓存次数,越高表明缓存使用率越高;
- cache eviction算法:即清空策略,其定义了当元素超过cache本身容量时的处理方法,比如LRU算法,将最近最少用的元素清除;
- time-to-live: 定义了cache元素何时被清除;
“多久更新,如何更新”
2.1、Cache的分类
从调用者与cache的交互方式上,我们可以分为三大类:
- 应用层cache:首先从cache取,命中则返回;如果未能命中,则直接去取数据源本身;
- L2 Cache,所谓的中间层cache, 调用者和ache之间隔了一层proxy, 调用者意识不到cache的存在; 当cache未能命中时,由proxy访问数据源获取数据加入cache;
作为用户访问云服务的重要手段,SDK往往充当了proxy的角色,其内部加入L2 cache,可有效降低对服务本身的访问压力;
- 混合Cache: 如果proxy和L2 Cache界限不明显,很多时候合二为一,即为混合cache
从架构上划分,cache可分为本地与分布式;
- Local Cache:
- 所有元素存在本地内存,对于JAVA而言其上限即为JVM的heap大小;
- 同一进程内部,响应迅速
当然其缺点也很明显,首先本次缓存与程序紧耦合,多个应用程序无法共享缓存,各应用和集群节点都必须维护自己的单独缓存,也是一种浪费;另外,为了保证多个进程间的数据一致性,程序相对不易维护;
- 常见实现:ConcurrentHashMap,ehcache, Spring Cache
其中Ehcache的缓存数据有两级:内存和磁盘,与一般的本地内存缓存相比,有了磁盘的存储空间,将可以支持更大量的数据缓存需求;
直接实现
a. 成员变量或局部变量实现
|
|
以局部变量map结构缓存部分业务数据,减少频繁的重复数据库I/O操作。缺点仅限于类的自身作用域内,类间无法共享缓存。
b. 静态变量实现
最常用的单例实现静态资源缓存,代码示例如下:
|
|
O2O业务中常用的城市基础基本信息判断,通过静态变量一次获取缓存内存中,减少频繁的I/O读取,静态变量实现类间可共享,进程内可共享,缓存的实时性稍差。为了解决本地缓存数据的实时性问题,目前大量使用的是结合ZooKeeper的自动发现机制,实时变更本地静态变量缓存:
TODO:实际项目:相对静态数据,比如元数据可以基于本次cache加速,
美团点评内部的基础配置组件MtConfig,采用的就是类似原理,使用静态变量缓存,结合ZooKeeper的统一管理,做到自动动态更新缓存,如图2所示。
美团
TODO1:根据期望到货时间排序通知,需要考虑加入本地cache, EBOOK – REDIS IN ACTION
TODO2: Pub/Sub:在更新中保持用户对数据的映射是系统中的一个普遍任务。Redis的pub/sub功能使用了SUBSCRIBE、UNSUBSCRIBE和PUBLISH命令,让这个变得更加容易。到货通知
Java Cache Benchmark
sping cache
- 分布式cache特点:
- cache元素分布在集群的不同的服务器中;
- Cache size为每个cache分片之和,可以远远大于单台JVM可保存的cache数量;
- cache可水平扩展
目前的实现memcached、redis和tair;
分布式cache性能对比
redis
Understanding transaction pitfalls
网络爬虫
stakcoveflow架构
2.2、供应链的Cache
Global Cache
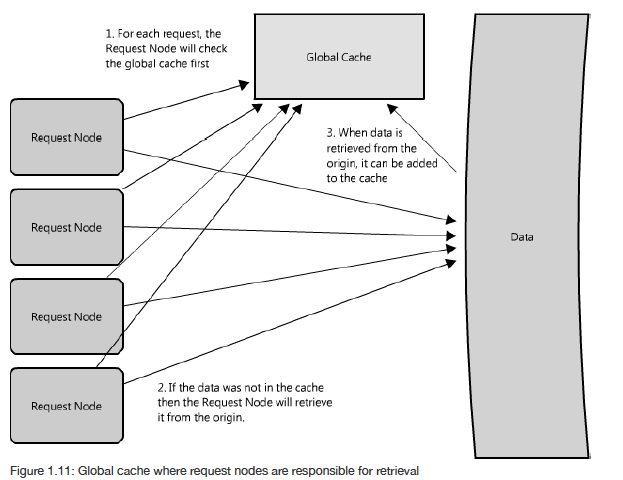
网络拓扑同步用到了global cache,流程:
- sync服务
2、SDL流程
Secure Software and Secure Development Tools
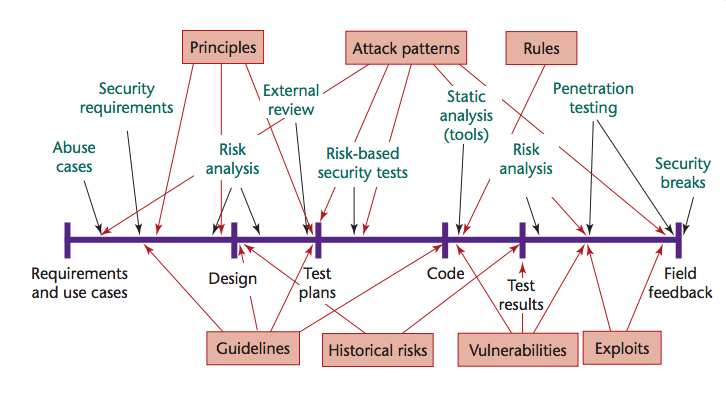
- 安全本身就是设计需求:尽可能早的考虑安全和合规;
- 攻击面分析:基于最小权限和分层防护;
- 利用威胁模型:面对威胁场景,利用结构化的方法帮助团队更有效的识别安全薄弱环节、以及应对策略,建立合适的迁移方案;
手段:
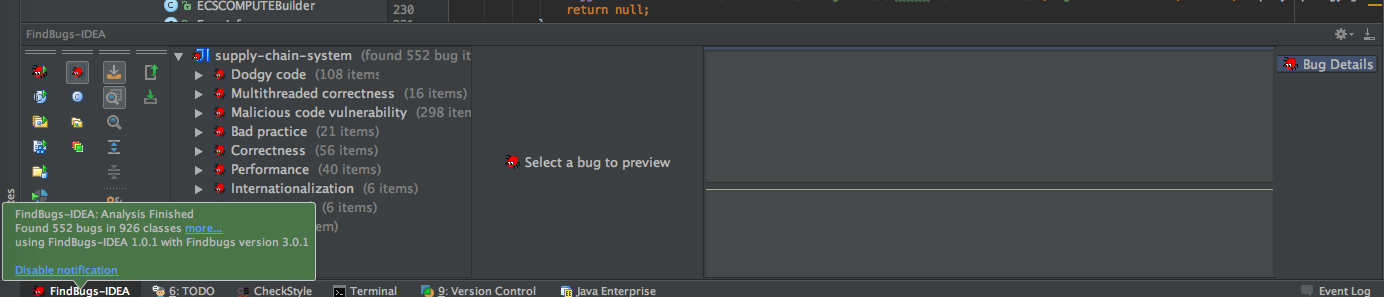
- 静态扫描工具: C版本的Klocwork,静态代码分析,内存泄露等,开源审计;JAVA的findbugs
其中JAVA的静态扫描示例:
3、Redis
Redis基于TCL编写测试框架;
4、mybatis支持缓存
- 二八原则为知识体系构建;
- 看书做笔记,零碎记录,再加工为文章;
- 讲给别人听,熟练到改变了大脑,你才不会遗忘。
5、数据库缓存支持
5.1 spring支持缓存
Spring Boot中的缓存支持(一)注解配置与EhCache使用
5.2 mybatis支持缓存
- 前提
多数 ide 会提示声明一个静态常量 serialVersionUID(版本标识), 类已经序列化,serialVersionUID是JAVA的序列化过程中用于标识和识别序列化类的;
Serializable 则是应用于Java 对象序列化/反序列化, 作用:
- 用于网络传输;
- 用于本地磁盘保存;
- MyBatis配置:二级缓存
- 全局配置变量参数 cacheEnabled=true
- 该select语句所在的Mapper,配置了
或 节点,并且有效 - 该select语句的参数 useCache=true
- MyBatis配置:第三方缓存
- Ehcache
框架实现:

调用过程分析:
|
|
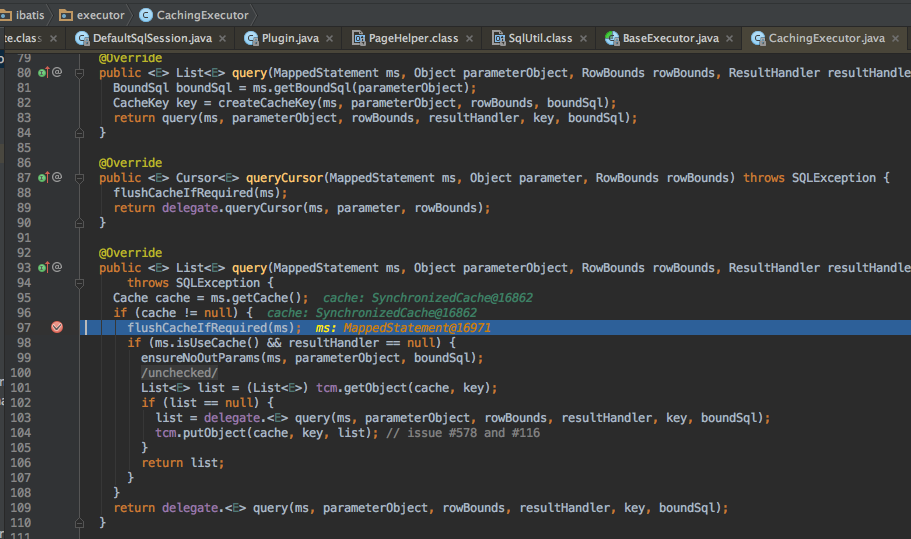
其中cache执行器CacheingExecutor, 如果配置了使用cache的标志(在mapper.xml中),直接从cache中获取;
5.3 Spring Boot 整合 Redis 实现缓存操作
6、消息队列
用途:解耦调用方和被调用方
TODO:
- 定时任务修改为通知,你完了通知为,我继续
- 从
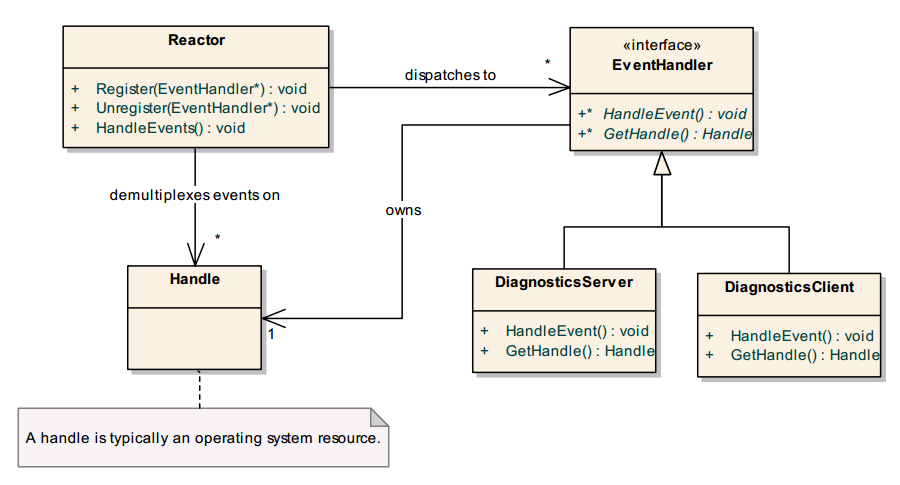
6.1、事件探测
在一些文献中关于 reactor 的描述中,定义了一个工具,即 synchronous Event Demultiplexer , 该分离器由 reactor 调用等待已经注册的 Handles 的事件。
该事件分离器一般由操作系统提供,比如 poll() ,select() 和 WaitForMutipleObjects() 。
6.2、实现机制
EventHandler 和 Reactor 之间的合作关系类似OBSERVER模式中的observer和它的对象。
为了将Reactor和它的事件处理器解耦,同时Reactor仍能够通知到他们,每个具体的事件处理器必须关联一个唯一的instance。这里的C实现中,采用void 作为通用类型以描述 *EventHandler 接口。
- 事件处理接口:EventHandler.h
|
|
8、MVC测试与cookie
应用REACTOR模式的主要结论如下:
- 遵循single-responsibility原则的好处:采用REACTOR模式,每种责任被封装并相互之间解耦,导致高内聚,因此简化了后续维护。比如在事件探测中平台相关的代码可以从应用中解耦,极大的方便了单元测试。
- 遵循open-closed原则的好处:新的责任只需创建新的事件处理器,无需影响现有代码。
- 统一了事件处理:尽管REACTOR模式集中于句柄,但其可以扩展至其他任务。Reactor加入timer支持(平台相关,比如基于信号或者线程),当同步事件分离器触发后可以设定一个超时,以避免重入问题和竞争条件。
- 提供了一种并行读的方案:采用REACTOR方案可以有效避免并行读事件处理中的阻塞现象,其本质是一个非抢占式的多任务模型,每个具体的事件处理器必须确保其不能执行可能导致其余事件处理器饥饿的操作。
- 类型安全的折中:由于所有的事件处理器抽象为void *,当由void指针转化为具体的事件处理指针时,编译器并没有相应的机制处理转化错误。同样的问题在OBSERVER模式中也存在,解决方法都是一致的:为不同类型的事件处理器定义单独的通知函数,利用EventHandler绑定事件处理器和其他函数。
8、前台后台分离
对于类似订单中心的多Key类业务,在数据量较大,需要对数据库进行水平切分时,对于后台需求,采用“前台后台分离”的架构设计方法:
- 前台、后台系统web/serveive/db分离解耦,避免后台低效查询引发前台查询抖动;
- 采用前台与后台数据冗余的设计,分别满足两侧需求,比如在tboss_data中增加了产品等;
- 采用外置索引(例如ES搜索系统)或者大数据处理(例如HIVE)来满足后台变态的查询需求;
9. ereka loadbanlacner
|
|
9、总结
Reactor模式通过对不同责任的解耦和不同模块的封装简化了事件驱动型应用的设计。关于该模式更多的讨论可以参考面向对象的软件模式卷2。