
VDI优化涉及到诸多系统的方面,整个系统的大框架如图所示:
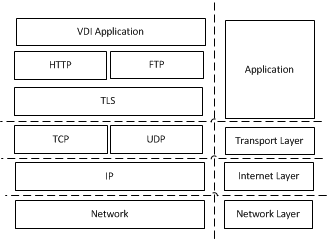
VDI APP层
APP内部实现架构选择,比如是采用多进程模型还是单进程模型;
HTTP层
目前整体流程基于过程式交互方式,可以改为基于事情驱动的状态机实现方式;
SSL层
首先评估SSL的overhead到底有多大,以及主要瓶颈,针对性的进行优化;
SSL双方采用的版本也影响overhead,目前SSL的版本号有SSL2.0 SSL3.0,TLS1.0(SSL3.1),TLS1.0(SSL3.2)和TLS1.0(SSL3.3)。版本号的协商基于如下公式:
min(max. client supported version, max. server supported version)
TCP/IP层
关于序列号
- TCP中双方的握手和分手过程,所有报文的
TCP Segment Len都为0。 Window就是滑动窗口,用来解决流控问题,即如何提高网络吐吞率,主要涉及到拥塞控制的参数调整。Sequence Number用来解决乱序问题,即我发送了多少加多少(对于三次握手阶段,以报文个数为单位,即在对方Acknowledgment Number基础上递增1;对于数据发送阶段,以字节数为递增单位,即在自己现有的Sequence Number上递增TCP Segment Len)。Acknowledgment Number用于确认收包,解决丢包问题,即我收到了多少加多少(对于三次握手阶段,同样以报文个数为递增单位,即在对方Sequence Number的基础上上递增1;对于数据发送阶段,也同样以字节数为递增单位,即在自己现有的Acknowledgment Number上递增TCP Segment Len)。如图所示:
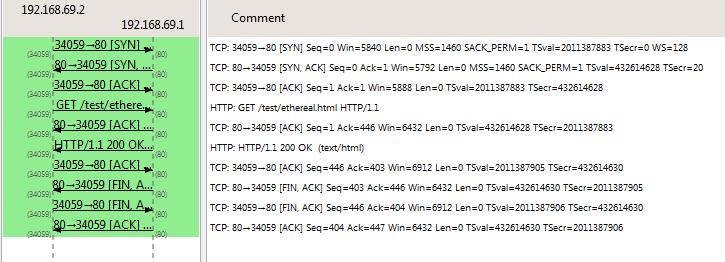
其中客户端192.168.69.2和服务器192.168.69.1的三次握手中,服务器的seq是自己产生的,ack则是在收到客户端的SYN报文后递加1(客户端的seq + 1),表示收到了客户端的连接请求;客户端的seq也是自个产生的,发送了一个SYN,就递加1,ack则是在收到服务器的SYN/ACK报文后在服务端的seq + 1。
在TCP连接建立后,客户端向服务端发送一个TCP Segment Len为445字节的分片#4,当前seq为1(相对序列号),不管是否送达下一个分片#6发送时,其seq会忠实地递增445字节,变为446。服务端收到分片#4后,将ack递增445字节。
总之,Sequence Number和Acknowledgment Number像极了人的奋斗过程,前者好比付出,后者好比收获,但是付出不一定有收获(如果得到ACK确认则成功,否则失败)。
网络层:
主要涉及到网络接口驱动的实现优化,比如中断轮询模式选择,是否启用DMA等。
加入LRU Cache
LRU即Least Recently Used,是一种在cache中广泛应用的算法,保持经常访问的数据节点在cache中,如果某块节点很少被访问,在达到某种阈值之后就把它交换出去,这就要求查找和插入删除都要快。本系统采用双向链表和哈希表实现,主要利用了双向链表的插入和删除操作和哈希表的查找操作,数据结构定义如下:
|
|
对应的操作主要就是get和put。
- 创建LRU cache。
|
|
- 销毁LRU cache。
|
|
- 插入LRU node。
基本思路:如果待插入数据在cache中没有(cache miss)且没有超出cache容量,就为其分配节点,插入至链表头部,表示最近访问,同时插入哈希表当中;如果待插入数据已经存在且cache已经满了,那么首先找到最后一个元素,意味着最近没有访问,从哈希表中删除,然后从双链表中删除。
|
|
- 查找LRU node。
如果cache miss也就罢了,如何找到了,在返回该节点之前因此需要将其移到链表的头部,因为查找某个节点意味着对该节点有了最新的访问。
|
|
实际上两个辅助函数LRU_moveToHead和LRU_removeLast的实现值得注意:
其中LRU_moveToHead的基本实现思路就是先促成当前节点前后两个节点的牵手,然后再往前坐链表头,最后修改first和last节点。
|
|
TLS层的优化点
TLS连接的建立和关闭过程如图:
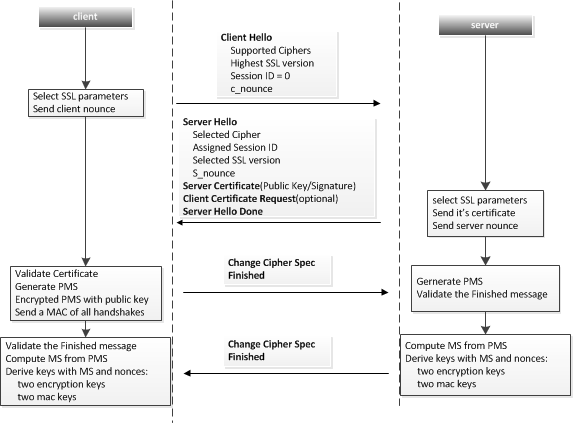
在TLS中频繁分配释放的内存主要有以下几类:
- 哈希描述符和哈希值;
- 密钥,比如masterkey为48字节;
- 典型的小块内存,一般为64字节和96字节;
Memory Pool的主要设计思路:
- 每块内存都看做一个对象,预先分配好一定数量的对象,即所谓的内存池;
- 定义get和put方法,一般成对出现,这样保证了预分配的对象数量可控;
- 内存池内的每个对象用单向链表维护,具体操作见图;
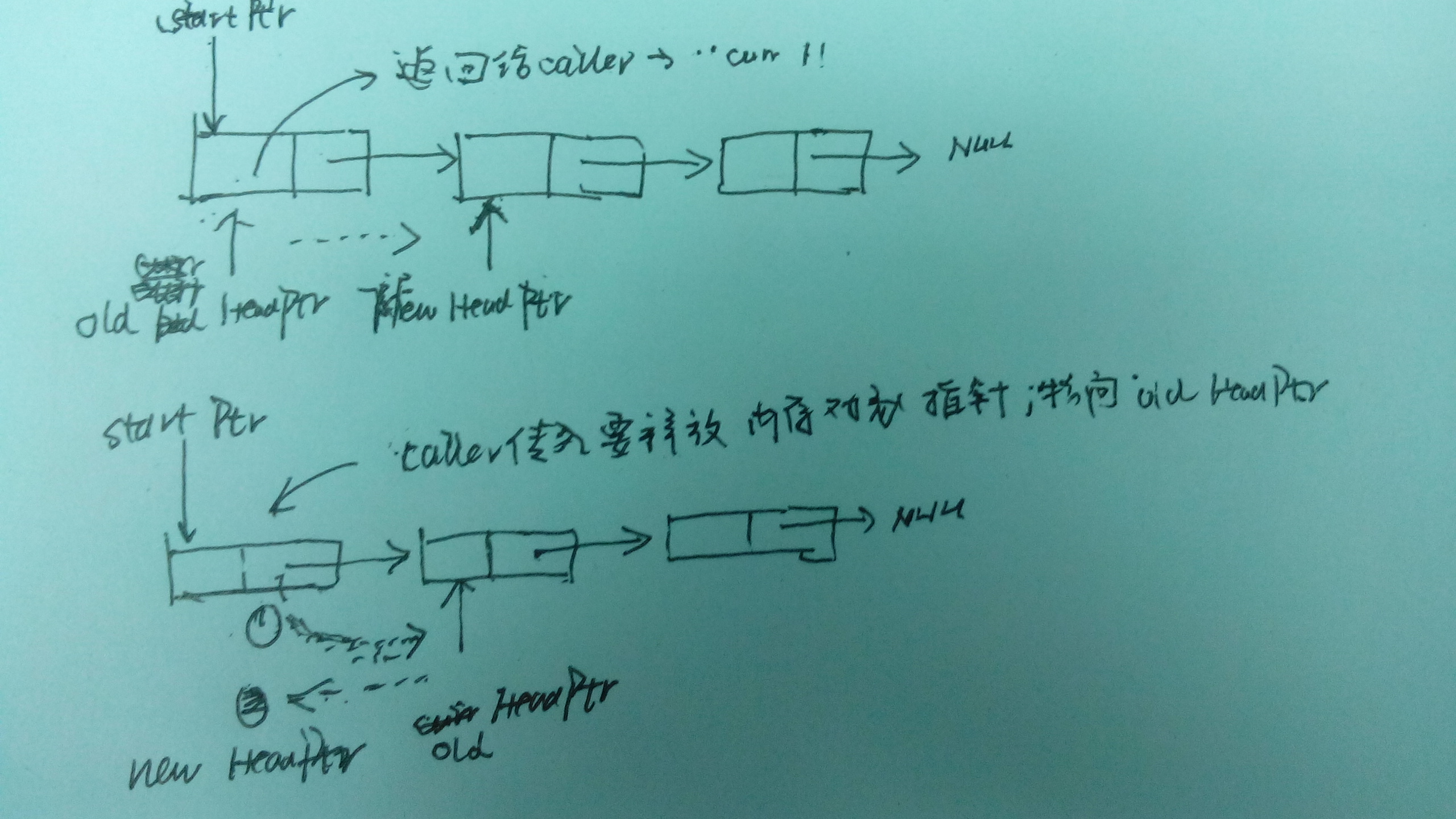
对SSL的握手过程进行对比测试,结果表明在使用mem pool的性能提升为8%左右,似乎并不理想,看来在SSL握手中此类内存的分配释放并不是影响性能的主要因素。
充分利用硬件加速
对于计算密集型的加解密运算,首先想到的就是利用硬件进行加速,这里有两个方面的考虑:
- 主存和硬件加速单元之间的IO: 数据从主存搬移至硬件,硬件将结果返回给主存
- 对硬件处理结果的查询方式选择: 轮询还是中断?
针对上述考虑,采取的措施如下:
- 分析分析硬件加速的实现代码,发现其涉及到非常多固定大小内存的分配与释放,依然采用上文中的cache机制,需要注意的是硬件读写时要求地址对齐,因此对cache实现稍作修改,加入内存对齐处理。测试结果显示,后者能将性能提升50%左右(见下图)。
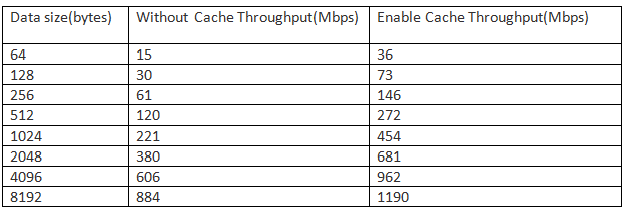
- 利用DMA进行数据拷贝避免动用CPU在主存和硬件加速单元之前拷贝,测试结果表明两者的性能差异大约在2倍左右。
- 分别实现中断模式和轮询模式,对比后发现轮询模式下效率更高,因此选择了轮询模式。
整体而言,采用硬件加速就是在充分利用压榨硬件计算性能的基础上尽可能减少内存拷贝和IO消耗,最后性能平均提升大约十倍左右。